Creative robots: GAN you believe it?
Creative robots: GAN you believe it?
Come along with me as we talk about the possibilities with GANs and see how easily they can be implemented, along with the computing requirements necessary!
I'm a software engineer working at Kainos in the Applied Innovation team, a team that works with customers to use and develop tools beyond the immediate horizon for customer proof-of-value. As part of that vision, Machine Learning and Artificial Intelligence has been an important research area for Kainos, which has led me to look at GANs, or Generative Adversarial Networks.
What's a GAN?
I've linked to an in depth explanation of what they are and how they work, but basically it's a battle between two creative neural networks. One is a generator, capable of generating new data. It starts off generating just random noise then learns what to change to make its output more convincing. The other is a discriminator, whose job is to tell the difference between an output from the generator (fake data) and a real example (training data). Both can learn from their mistakes to prevent making them in the future, so they both get better over time.
You can think of it like the ongoing battle between an art forger (generator) and a fraud detector (discriminator). The forger tries to copy the style of genuine paintings but isn't very good at it to start with. The fraud detective also starts off with only basic techniques to detect forgery. However, as their opponent gets better they are both forced to improve their techniques to avoid getting left behind.
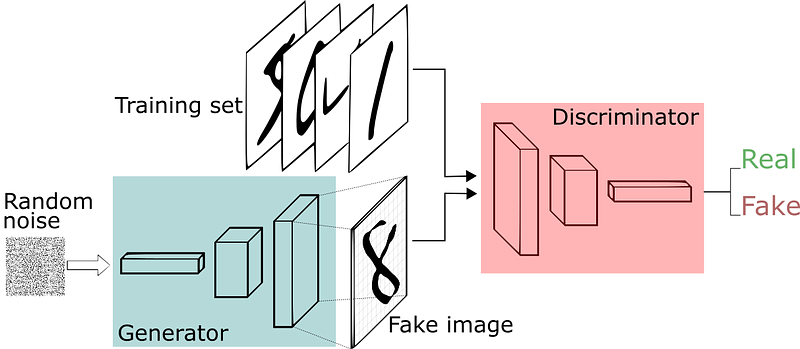
How an OCR (Optical Character Recognition) GAN works, from SkyMind
What can GANs do?
There are many different types of GAN designed for different purposes. GANs can be used for image generation, feature transfer, object removal, image repair, ageing, deep fakes, pose estimation, enhancing image quality, generating synthetic test data, security, robotics and lots more. They can also be applied to important tasks like writing legal contracts or inventing new medicine. Most of my efforts have focused on image generation and completion, as tools are more readily available to help with this (for example, nearly all of these).

CycleGAN: learns how to apply a feature to images (e.g. a type of animal or season)
Let's see an example of GAN in action!
One of our customers was building a website that hosts real estate images. An interesting thing that was mentioned by the estate agent was how people buy into new property. They said, 'People don't buy the property, they buy the life they want.' For most buyers, looking at properties online is their first port of call, where first impressions are made and the listed photographs might be what ultimately results in a sale if a buyer can picture themselves living there.
Estate agents already have the ability to add furniture into an empty room and cover up blemishes in the photo using imported furniture. However, our customer was interested to see if it was possible to remove furniture without having to cover it up again??? ??just reveal the room behind as it should appear. This opens up many possibilities:
- gives customers a better idea of the amount of space available
- not influenced/distracted by existing furniture, which won't come with the house anyway and may not be their style
- the room could even be personalised for the customer, with customised picture frames, carpet, wallpaper, etc.
This was an interesting and inspiring set of problems, but to keep the scope simple I decided to focus on just removing office chairs, as you can see from the diagram below. As these were plentiful in my office I could easily obtain images to use as test data. I also manually masked the chair instead of auto-detecting it as this wasn't my main focus (this would be possible using something like Mask-RCNN). A mask is an area of an image which is highlighted as being important. The masked area (shown in white below) is the part which will be altered by the image completion GAN.

An abstract overview of the process of removing a chair. Results are shown in the ??testing the model' section.
How would I implement this?
Now I had an idea of what I wanted to accomplish, I needed to choose a GAN implementation to use and decide which hardware to run it on. The best work in this area I could find online was in this Github repo by Jiahui Yu et al. It was published recently (January 2018), meaning the work of recent papers on the subject has been taken into account, and it's able to work with large, high quality images. You can see what it's capable of with this interactive demo.
What can I run it on?
We had a number of PCs available with Nvidia GTX 980's, but I decided to use the Nvidia Jetson TX2 (developer kit), a small, power-efficient 64-bit Linux computer designed for AI Computing. It has a more efficient GPU than the desktop, although it isn't as powerful. My main reason for using it was to see how viable running something like this is ??at the edge'??? ??for example, on a user's device which may not be very powerful. We also saw this as a chance to explore the Jetson's capabilities.
Jetson setup can be tricky as it has an unusual architecture, aarch64, instead of the usual amd64, which means some programs must be compiled from source. It can be extremely hard and/or time-consuming to get the program you want (in my case, TensorFlow) and all its dependencies installed and working. If you want to take advantage of a pre-built TensorFlow binary you'll need to jump through a lot of hoops including making sure you use the exact same CUDA, cuDNN and OpenCV versions. Compiling TensorFlow from source would have taken even longer??? ??this can take half an hour on an Intel i7, never mind a Jetson designed for efficiency.
In the end, I had to update Jetpack to v3.2 (reflashing the entire OS was the simplest option for me), build OpenCV from source (I used version 3.4.0), then find and install a custom-built pip wheel for TensorFlow 1.8.0. make sure you're using Python 3 if you're using the same implementation as me (generative inpainting by Jiahui Yu).
Time to start training! ?
Training the machine learning algorithm is the main task involved in this project. Both the generator and discriminator are used to learn from each other??? ??if one makes a mistake its loss increases and it will do things differently in future. They both work to minimise their mistakes. During training a model will be generated. This is where the algorithm stores its acquired experience of how to perform a task, in this case how to generate a life-like interior or how to discriminate between machine-generated and real interiors.
The Jetson usually has about 5.5GB of RAM available, so I decided to use an image size of 128x128 for training as this results in the use of about 4GB of memory, which is workable on both the Jetson and our desktop PCs with GTX 980's. I started off training with just 50 images of my office, focusing on features such as the doors, wall, ceiling and floor.

Examples of the 128x128 training images used
Now for a test?� ?
This is the output for the same input image and mask for each version of the Furniture Removal GAN. We can't expect perfection (or close to it!) with the limited amount of training data I used, but??? ??before reading further, which one do you think looks the best? Why?
 |
 |
 |
 |
Let's review how each version performed and see which one we like best. The number of epochs is the number of times each image was trained on??? ??in other words, any particular image will only be used once per epoch.
- This version was misconfigured to train only 1 epoch at 10,000 iterations/epoch. This setup told the program to use the training images only once but to expect 10,000 images, when only 50 were supplied. The pictures were also slightly larger than 128x128, meaning they were randomly cropped.
- I fixed the epoch configuration and trained for 30 epochs at 50 iterations/epoch. I chose 30 as a fairly low number to prevent reusing the same images too many times, as I was worried about overfitting, where the model matches a particular picture too closely and doesn't learn to include different variations of it. 50 iterations meant I used all 50 training images in each epoch. The pictures were still being randomly cropped.
- I manually cropped the training images to exactly 128x128, including the most important features in the image.
- I tried training for 100 epochs at 50 iterations/epoch. The result looks like it has been overfitted.
I think version 3 looks the best, as you can see white from the door frame bleeding in from the edges, the grey has a similar texture to the carpet and if you look closely, you can see some lines being connected as they should in the door frame at the left. Here are some other images with Furniture Removal GAN v3 applied.
 |
 |
 |
 |
How could this be improved?
- The training process should have much more data. The model performed very well considering the very small dataset of only 50 images, but ideally at least 2?�4 times the number of images should be used just of this room alone. Typical datasets can contain millions of images to provide a wider range of experiences to the training algorithm, allowing it to work in different environments.
- Using a GPU with more RAM would allow training with 256x256 (or larger) images, the same as the sample datasets in the repo I used. Improved training quality should help with the amount of accurate detail in the output images.
- A new and improved version has been developed by the same authors, although no source code has been published. It would be interesting to see how much better this is as it's supposed to handle freeform masks better (v1 is mainly for rectangles, although I used it with masks) and you can help it produce better output by annotating border lines.
 'The Master of Chairs'
'The Master of Chairs'
As you can see my work hasn't gone unnoticed within the team??? ??I'm now officially known as 'The Master of Chairs' due to my work on this! Looks like I've found my calling ?
This was a short research project where we achieved what we wanted??? ??to help us understand the utility and versatility of GANs and educate the company and customers about what might be possible tomorrow. I've since moved off this, but if you're interested in hearing more about it, or any other Applied Innovation projects, feel free to get in touch.