I joined Kainos in July as a placement student, and from there I took part in their 7 week AI Academy. The culminating event of the programme was to plan, develop, and present an individual Capstone project. The project was intended to develop our programming, data science, and client engagement capabilities.
I decided to focus on a project which extracts data from documents. To make it a bit more interesting however, I decided to use Sudoku puzzles as my document.
The digits in a Sudoku board are related to each other, so we can improve our accuracy by using context to our advantage. Not only will I extract the data from an image of the board, but I’ll solve the puzzle as well!
If you don’t know the rules of Sudoku, here they are:
- Every cell must contain a single number
- Only the numbers from 1 through to 9 can be used (no 0s)
- Each column can only contain each number from 1 to 9 once
- Each row can only contain each number from 1 to 9 once
- Each 3x3 box can only contain each number from 1 to 9 once
Level 0 – The Dataset
First thing’s first, we need some Sudoku boards! I found this dataset. It contains two copies of every board – one starting version and one completed version, and the annotations for each.

Level 1 – Board Extraction
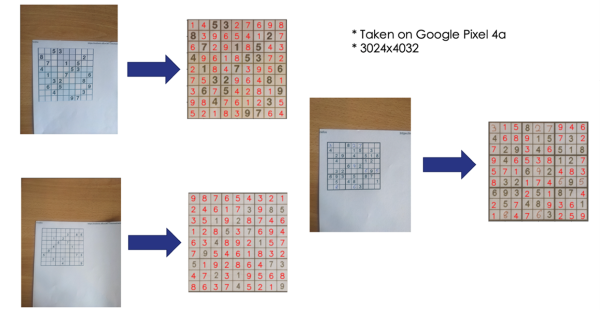
To make it as easy as possible to read the numbers, we need to crop out the board. I applied the following transforms using the OpenCV library in Python.
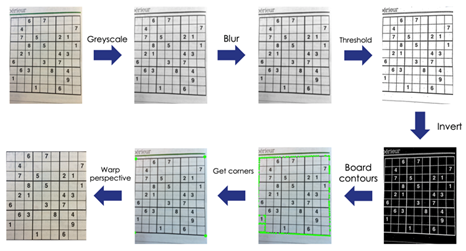
Level 2 – Digit Recognition
Great! Now that we have the cropped board, we have to read the numbers inside the cells. This is called Optical Character Recognition (OCR). We must be careful when reading a Sudoku board – if we classify just one digit wrong, the board might be invalid. In the following experiments, ‘Board Accuracy’ refers to the % of boards which were read perfectly; No digits were mis-classified.
Before trying to train our own model to read the numbers, let’s try to use AWS Textract to read the boards. Since the boards are basically tables, I think AWS Textract’s ‘Table’ feature will be perfect! Here is the result.

Ok – that’s not great! Maybe if we draw thicker lines to separate the cells?

I noticed that the outer cells weren’t being read well. Maybe if we add a border to the cropped image it will help?

Now combine both!

That’s better, but I wonder how AWS Textract would perform if we didn’t use the ‘Table’ feature at all?

Oh. Well that was easy! I wonder if we can beat AWS Textract with our own model.
First, we will try to train a Convolutional Neural Network (CNN) on the. The MNIST dataset contains thousands of handwritten digits like these:

Let’s train our CNN on these, and then see how it performs on our dataset. Here’s how we’ll evaluate our models:
- Cell-level accuracy: The % of cells our model correctly classifies across our entire test set. Higher = better.
- Board-level accuracy: The % of boards our model perfectly classifies across our entire test set. Higher = better.
- Macro-avg F1-score: The average of precision (“out of all the times we classified a digit as a 1, for example, how often were we right”) and recall (“out of all the 1's, for example, how often did we correctly classify them”). Higher = better. To learn more about F1-score click here.
The plot below is called a ‘confusion matrix.’ It makes it easy to see which digits our model is getting wrong. The x-axis is what our model thinks, and the y-axis is the true label. For example, this model classified 506 zeros as sevens. Ideally, we want there to be a diagonal line from top-left to bottom-right, which would indicate our model is performing well on all digits.
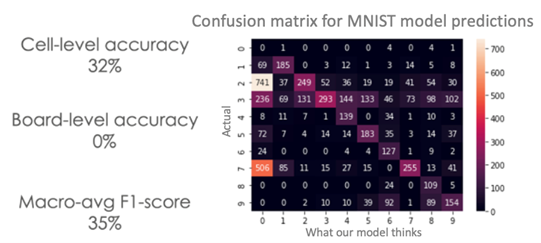
0% board-level accuracy! Clearly MNIST data won’t cut it. We must train the model on our own data. We can cut our boards up into cells so that we can train on individual digits.
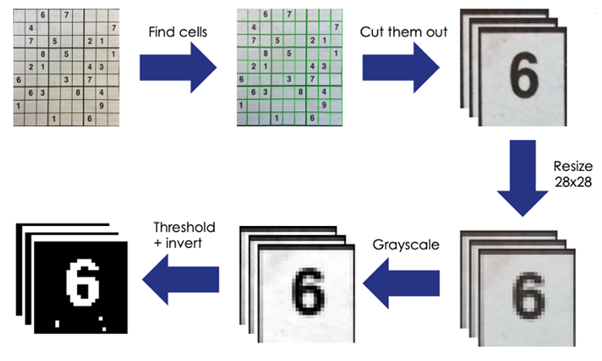
Now take a look at the results after training.
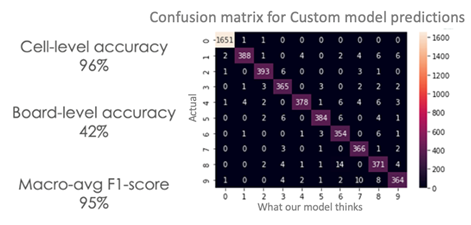
Wow! 42% board-level accuracy is our best so far!
I still feel like the MNIST dataset can help us though. Let’s try fine-tuning our MNIST model on our data. Fine-tuning is when you take a trained model (e.g. on MNIST digits) and resume training using slightly more specific data (e.g. Digits from Sudoku boards). How does our fine-tuned model perform?
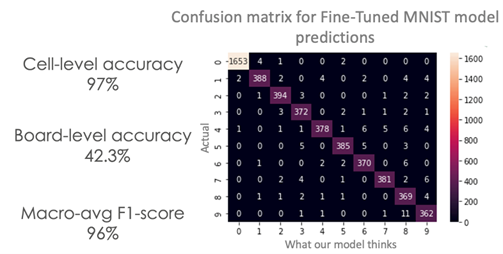
Great – now we have a model which perfectly reads 42.3% of our Sudoku boards. Here are some of the digits it’s getting wrong. Hopefully you can see where it got confused!

Level 3 – Thinking Outside the Box
At the minute, we’re just looking at each digit individually before making our final prediction. What if we considered the predictions of the cells in the same row, column, and box as the cell we’re currently looking at? That way, we can use the rules of Sudoku to our advantage. Here’s the algorithm I settled on.
For every cell:
Do:
pred = Next highest confidence prediction for this cell according to model
conf1 = Confidence of pred according to model
For every cell in the same row, column, or box as this cell:
conf2 = Confidence that this cell is pred according to model
If conf1 < conf2:
Remove pred from possibilities if not already removed
While conf1 < conf2.
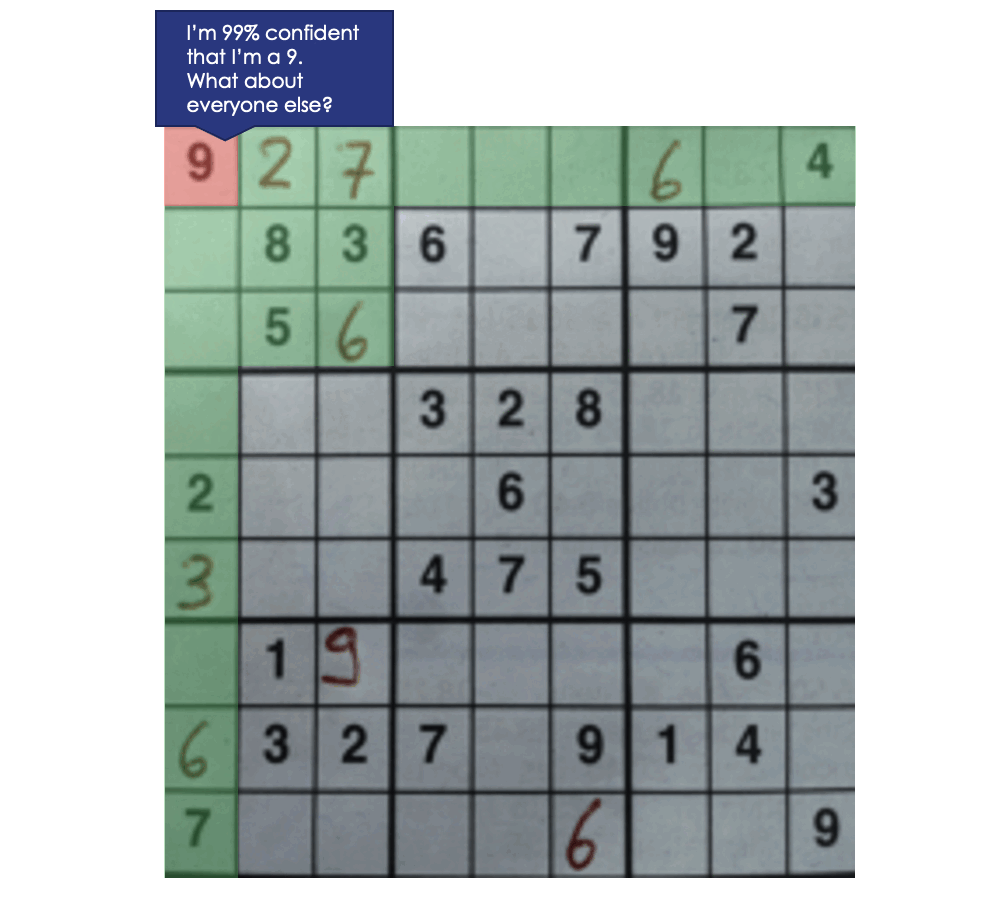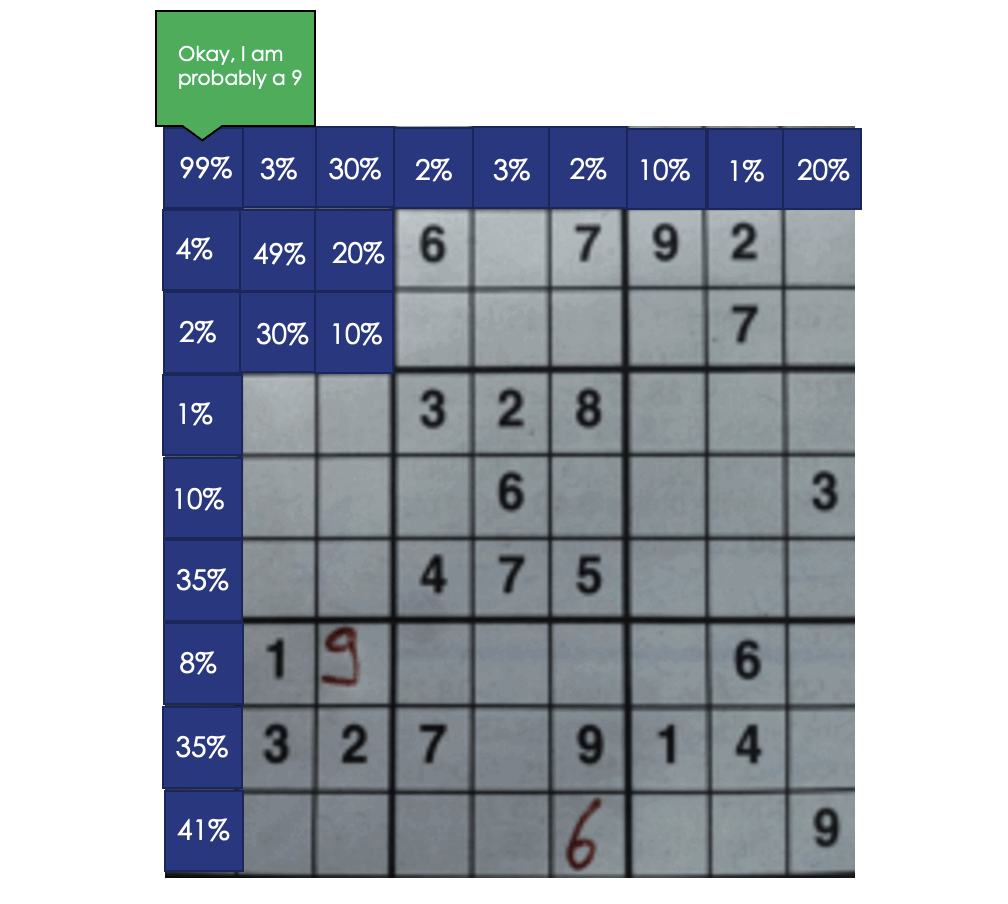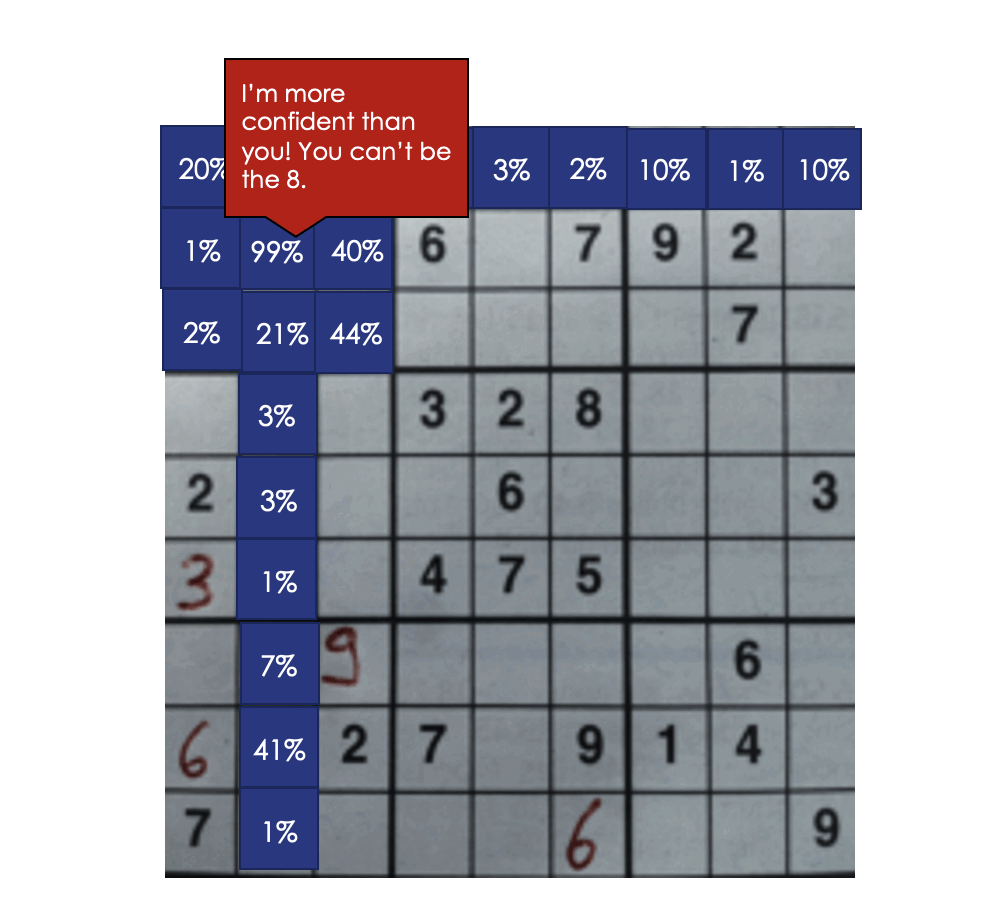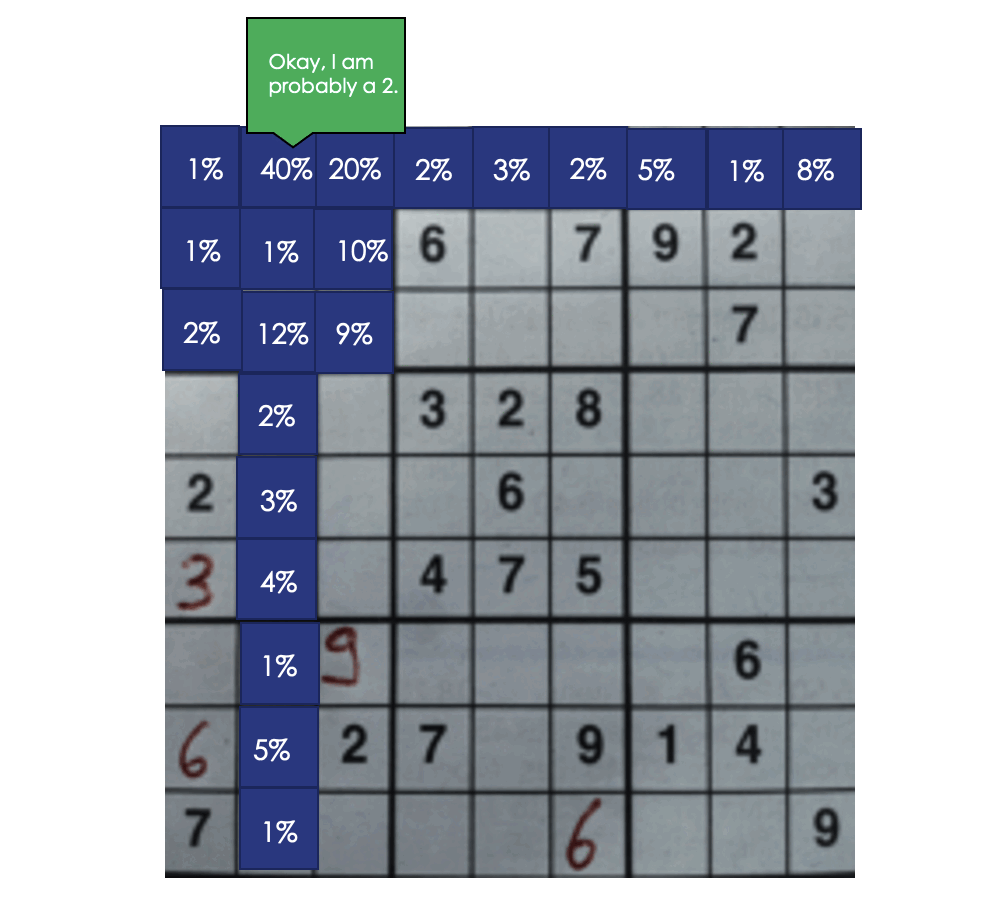
Using this context information increases our board-level accuracy from 42.3% to 57%!
We are evaluating our models on a combination of completed boards and starting boards. Starting boards are puzzles which haven’t been started yet. They are boards which are partially filled with printed digits. Usually, boards with less initial digits are more difficult puzzles to solve.
Completed boards are much harder to read perfectly because numbers are harder to read than blanks. Since we will usually be using this program when there are a lot of blanks, it makes sense to look at the board accuracy on the blank boards alone. We perfectly read 93.8% of the starting Sudoku boards in our test set.
Level 4 - Solving Sudoku
Now that we have read the Sudoku board, we can finally solve it. Sudoku is a type of exact cover problem, so it can be solved by an implementation of Algorithm X using dancing links. This algorithm solves the hardest Sudoku board in 188 nanoseconds!
Time to test it out!
General Applications
I don’t think a customer will be asking Kainos for a Sudoku solver anytime soon, so what was the point? A Sudoku board is just a structured document – a form. The same framework could easily be used to extract data from other types of documents.
For example, imagine a system which reads receipts from images. If a model thought that the ‘total amount’ of a receipt is £160, but the sum of the individual items is £180, then the model must be wrong. Armed with this context information, the model can try to fix its mistake. In this case for example, it may have misread the ‘8’ as a ‘6’.
Key Takeaways
I learned so much by working on this project. I had almost no Computer Vision experience when I started, but now I can at least do the basics in OpenCV. I learned how to use AWS Textract using the Python Software Development Kit (SDK), and how to train a CNN using Keros– both of which will be useful in the future.
Besides technical skills, I also got experience in managing a project end-to-end, prioritising work, and making everything easily reproducible. I also had the opportunity to improve my presentation skills by presenting the project on three occasions – once to senior members of the Data & AI Practice within Kainos, once in a technical deep-dive to the whole of Digital Services, and once to a group of students on the Earn As You Learn scheme here at Kainos.
There are two lessons I think everybody can take away from this project.
The first is the importance of contextualisation and having bespoke layers. In level 3, we increased model accuracy from 42.3% to 57% by using domain information/context. I encourage you to think about the project you’re working on now, and take a step back to see if you could do a similar thing.
The second lesson is the importance of optimizing for the right thing. Since a Sudoku board could be invalid if you mis-read one digit, we optimized for board-level accuracy rather than cell-level accuracy. This revealed we could use domain information (as discussed above) to improve our accuracy.
Keep your eye on the ball.
Acknowledgements
Thank you to all those involved in running the AI Academy, especially to my mentor Claire Houston. Their help and guidance throughout the first couple of months at Kainos has been fundamental to our success, and this project wouldn’t have been possible without them.